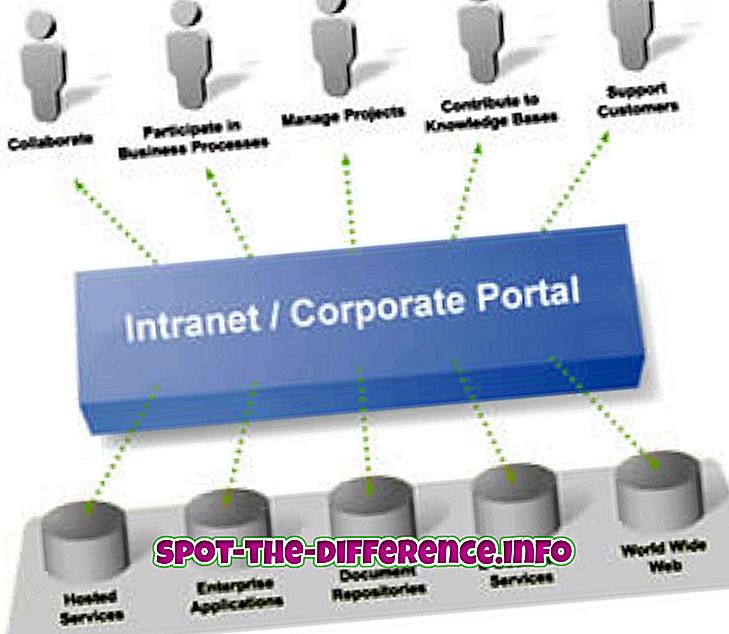
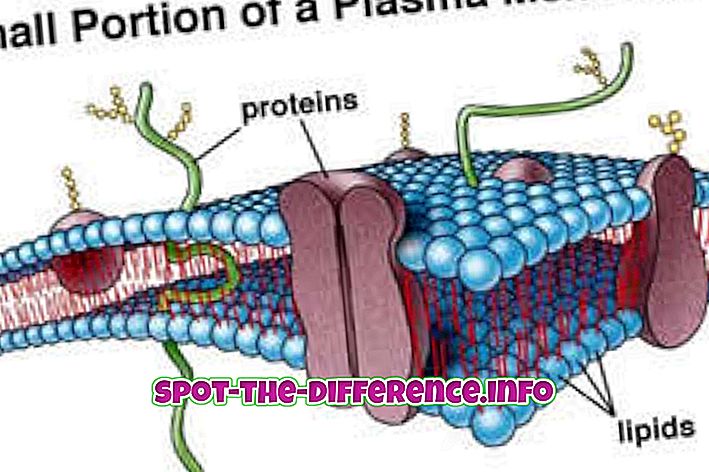
主な違い:データサイジングは、コンピュータサイエンスにおける情報ハイディングまたはデータカプセル化とも呼ばれ、オブジェクト指向プログラミング(OOP)で使用されるソフトウェア開発技術です。 これは主に、内部オブジェクトの詳細、すなわち変更される可能性が最も高いコンピュータプログラムの設計上の決定を隠すために使用されます。 抽象化は、コンピュータサイエンスにおけるもう1つのプロセスです。 実装の詳細をデータやプログラムから隠します。 プログラムで要求されている場合にのみ関連する詳細が表示されます。

データサイジングは、コンピュータサイエンスでは情報ハイディングまたはデータカプセル化とも呼ばれ、オブジェクト指向プログラミング(OOP)で使用されるソフトウェア開発技術です。 これは主に、内部オブジェクトの詳細、すなわち変更される可能性が最も高いコンピュータプログラムの設計上の決定を隠すために使用されます。 これは他のパートプログラムからデータを隠し、データやデザインの決定が変わっても、それらがプログラム全体に影響を与えることはなく、詳細が隠されていない部分だけに影響しません。 これにより、プログラムの一部を1回変更するだけでプログラム全体が変更される可能性は低くなるため、プログラム全体がはるかに安定したものになります。
データ隠蔽には、クラスまたはソフトウェアコンポーネントの特定の側面がそのクライアントにアクセスできないようにする機能もあります。 これは、プライベート変数などのプログラミング言語機能または明示的なエクスポートポリシーを使用することによって実現されます。 データ隠蔽は、ソフトウェアコンポーネント間の相互依存性を制限することにより、システムの複雑さを軽減し、堅牢性を高めます。

データ抽象化により、プログラマーは一度にいくつかの概念に集中できるように細部を減らして除外することができます。 ユーザーが必要とする詳細のみが表示されますが、それ以外の詳細および情報はすべて隠されています。 これにより、利用可能なデータが合理化されるため、ユーザーはその時点で不要な詳細を処理する必要がなくなる可能性があります。
システムは複数の抽象化層を持つことができます。 各層は異なる意味を持ち、異なる詳細を隠します。 ウィキペディアはこの例を挙げています:低レベルの抽象化層はプログラムが実行されているコンピュータハードウェアの詳細を明らかにし、高レベルの層はプログラムのビジネスロジックを扱います。
データ隠蔽とデータ抽象化の主な違いは、データ隠蔽はプログラムの他の部分からデータを隠すことです。 このデータは、プログラマがデータを表示するためにコードを書き換えるまで、それが隠されているプログラムの部分から利用することはできません。 ただし、データ抽象化では、データが完全に隠されているわけではありません。 現在関連性がないため、表示されていません。 データが関連性を持つようになったら、それが表示されます。